Grundlagen
Die Daten wurden in einer Exeldatei ausgegeben. Zu Beginn sortierte ich alle unvollständigen Fragebögen aus. Anschließend überprüfte ich alle Fragebögen auf Plausibilität. Einige Daten konnte ich nicht verwenden, da sich der Chronotyp nicht berechnen lässt wenn an allen Tagen der Woche ein Wecker verwendet wird. Schließlich blieben 155 Datensätze übrig, die ich zur Auswertung heranziehen konnte.
Für die statistische Auswertung nutzte ich als Grundlage die 7. Auflage des Buches “Angewandte Statistik” von Lothar Sachs, erschienen 1992 im Springer-Verlag.
Zunächst werde ich meine Daten auf Normalverteilung mittels Χ²-Anpassungstest prüfen. “Ein Anpassungstest prüft die Nullhypothese (H0): F(x)=F0(x) gegen die Alternativhypothese: F(x)≠F0(x).” (S. 420). Prüft man auf Normalverteilung sollte die Stichprobenanzahl 60 nicht unterschreiten. Weiterhin sollte es mindestens 7 Kategorien geben. Dabei sollten pro Kategorie mindestens 2 Werte vorhanden sein. Sonst werden diese Kategorien mit einer benachbarten Kategorie zusammengeführt.
Der Test führt eine Prüfgröße X̂² ein, welche kleiner sein sollte, als X̂². α bezeichnet dabei das Wahrscheinlichkeitsniveau auf dem geprüft wird.
Zur Berechnung vonwerden folgende Werte benötigt:
- k – Anzahl der Klassen
- b – Klassenbreite
- v – Freiheitsgrad ( v=k-1)
- Bi – beobachtete Häufigkeit einer Kategorie
- Pi – Wahrscheinlichkeit dafür, dass ein zufälliger Wert in der Kategorie i liegt
- Ei=n*pi – ist demnach die erwartete Häufigkeit der Kategorie i.
Nun kann man X̂² wie folgt darstellen:
Um gegen eine Normalverteilung zu prüfen benötigt man noch die Standardnormalverteilungsvariable z. z ist demnach die Funktionsvariable der Standardnormalverteilungsfunktion:
Für einen bestimmten Wert x kann mit Mittelwert und Standardabweichung z und damit auch f(z) berechnet werden. In der Auswertung wird außerdem noch K verwendet, welches multipliziert mit der Wahrscheinlichkeit die erwartete Häufigkeit ergibt.
In der zweiten Frage verbirgt sich die Frage nach Konvergenz. Ich werde allerdings nur den Korrelationskoeffizient berechnen und die Steigung der Regressionsgeraden.
Ich möchte n Wertepaare der Form (Xi|Yi) auf Konvergenz prüfen. Dazu betrachtet man nur die Differenzen der Koordinaten zu deren Mittelwert. Nun summiere ich das Produkt der X-Differenz und der Y-Differenz auf und teile es durch die Wurzel aus dem Produkt der Summen der Quadrate der Differenzen. Allgemein wird r wie folgt ausgedrückt:
Der Korrelationskoeffizient ist ein Maß für die Stärke einer Linearen Abhängigkeit. Um das Rechnen zu vereinfachen, kann man ihn umformen zu
Benötigt werden jetzt nur noch:
Als letztes statistisches Mittel nutze ich den t-Test. Dieser einfache Test prüft das sogenannte Fisher-Behrens-Problem, also ob zwei Mittelwerte gleich sind, bei ungleichen Varianzen. (Vgl. Sachs 1992, S.355). Die Prüfgröße ist dabei t. Geprüft wird gegen die Studentverteilung.
Wenn der Stichprobenumfang ausreichend groß ist, kann man auch gegen die Standardnormalverteilung prüfen, also gegen z.
Ergebnisse
Da die meisten statistischen Tests eine normalverteilte Grundgesamtheit voraussetzen, prüfe ich zunächst auf Normalverteilung. Ich nutze dazu den X2-Anpassungstest.
| x | B | Bx | Bx² | x-x̅ | ẑ | f(ẑ) | E=f(ẑ)*K | B-E | (B-E)²/E |
| 1:00 | 3 | 3 | 3 | -2,92 | 2,06 | 0,0478 | 5,229 | -2,229 | 0,950 |
| 2:00 | 16 | 32 | 64 | -1,92 | 1,35 | 0,1604 | 17,546 | -1,546 | 0,136 |
| 3:00 | 45 | 135 | 405 | -0,92 | 0,63 | 0,3271 | 35,769 | 10,231 | 2,926 |
| 4:00 | 47 | 188 | 752 | 0,08 | 0,05 | 0,3984 | 43,579 | 3,421 | 0,269 |
| 5:00 | 27 | 135 | 675 | 1,08 | 0,73 | 0,3056 | 33,428 | -6,428 | 1,236 |
| 6:00 | 9 | 54 | 324 | 2,08 | 1,41 | 0,1476 | 16,145 | -7,145 | 3,162 |
| 7:00 | 5 | 35 | 245 | 3,08 | 2,10 | 0,0440 | 4,813 | 0,187 | 0,007 |
| 8:00 | 1 | 8 | 64 | 4,08 | 2,78 | 0,0084 | 1,028 | 1,972 | 3,783 |
| 9:00 | 2 | 18 | 162 | 5,08 | 3,46 | 0,0010 | ^ | ||
| Σ | 155 | 608 | 2694 | 204,595 | -48,595 | X̂²=12,469 |
Damit ist gegen die Normalitätshypothese nichts einzuwenden. Die Daten können also annähernd normalverteilt angenommen werden und die Grundgesamtheit als normalverteilt.
So wie der Chronotyp sollten auch natürliche Aufwach- und Einschlafzeit normalverteilt sein. Deswegen habe ich auch diese Größen auf Normalverteilung untersucht und kam zu folgendem Ergebnis:
| natürliche Einschlafzeit | Chronotyp | natürliche Aufwachzeit | |
| Anzahl Klassen | 7 | 8 | 7 |
| Mittelwert | 23:59 Uhr | 3:55 Uhr | 7:54 Uhr |
| Standardabweichung | 1,79h | 1,42h | 1,20h |
| X² | 5,92 | 12,469 | 8,62 |
| Satistische Signifikanz | 50% | 95% | 90% |
Die statistische Signifikanz der Einschlafzeit war überraschend gering. Wahrscheinlich wird die Normalverteilung durch sekundäre Faktoren verzerrt, die ich zur Zeit nicht überblicken kann (Abendessen mit der Familie, Training im Verein…). Für die natürliche Aufwachzeit dagegen kann ich die Normalitätshypothese annehmen.
Nun gibt es noch weitere Größen: Schlafdauer, persönliche Zeit am Morgen und Schulweg sind alle nach unten begrenzt. Keine der Größen kann kleiner 0 werden. Deswegen können diese Größen nicht normalverteilt sein. Wahrscheinlicher ist eine logarithmische Normalverteilung. Da die meisten statistischen Tests aber eine annähernde Normalverteilung voraussetzen, habe ich trotzdem überprüft, ob ich diese Größen vereinfachend als annähernd normalverteilt voraussetzen kann.
| Schlafdauer | Persönliche Zeit am Morgen | Schulweg | |
| Anzahl Klassen | 6 | 7 | 8 |
| Mittelwert | 7:58h | 68,84 min | 29,74 |
| Standardabweichug | 1,24h | 23,82 min | 17,44 min |
| X² | 5,84 | 3,28 | 9,17 |
| Statistische Signifikanz | 70% | 70% | 80% |
Man sieht, dass es sich um keine exakten Normalverteilungen handelt. Während ich den Schulweg noch als annähernd normalverteilt annehmen kann, kann ich das für die Schlafdauer und die persönliche Zeit am Morgen nicht.
1. Beginnt die Schule zu zeitig? Und wenn ja, was wäre ein optimaler Schulbeginn?
Als optimalen Schulbeginn lege ich die früheste Zeit fest, zu der ein Schüler ausgeschlafen in der Schule sein kann.
Dazu berechne ich für jeden Teilnehmer die Summe aus natürlichem Aufwachzeitpunkt und Dauer des Schulwegs. In der Woche ist zwischen Aufwachzeitpunkt und Schulbeginn minus Dauer des Schulwegs im Durchschnitt noch eine Stunde Differenz. Diese wird zum Frühstücken, im Bad oder in der Schule zur Vorbereitung auf den Unterricht genutzt. Ich nenne diese Zeit „persönliche Zeit am Morgen“. Ich vermute, dass diese Zeit sich ändern würde, würde die Schule zu einer anderen Zeit beginnen. Zum Beispiel bräuchten manche Schüler bei einem zeitigerem Beginn dann länger, um munter zu werden, andere würden lieber länger schlafen als zu frühstücken.
Genauso kann man auch einen Zusammenhang zwischen Schulweg und Chronotypen vermuten. Schüler, die eine späten Chronotypen haben nehmen lange Schulwege vielleicht nicht so gerne in Kauf wie Menschen mit einem zeitigem Chronotyp. Dafür gehen Schüler mit einem späten Chronotypen, die in der Nähe der Schule wohnen lieber auf unsere Schule als einen längeren Weg zu einer anderen. So ließen sich auf jeden Fall Zusammenhänge erklären.
Um diese Fehler zu vermeiden betrachte ich zunächst verschiedene Varianten. Einmal nehme ich für jeden Schüler unverändert die Zeit, die er bisher brauchte vom Aufstehen bis zum Schulbeginn. Dieser Fall gilt auch kurzfristig für die Zukunft. Einmal rechne ich mit dem individuellem Schulweg wie bisher, aber berechne für die persönliche Zeit am Morgen den Durchschnitt (ca. 67 min) und wende diese auf alle an. Diese Variante gilt eher mittelfristig, da die Schüler auch in den nächsten Jahren denselben Schulweg zu bewältigen haben. In der letzten Variante rechne ich für alle Schüler mit dem allgemeinen Durchschnitt der persönlichen Zeit und des Schulwegs (ca. 1h 34 min). Auch hier vereinfache ich zu 1:30h. Die letzte Variante bietet die besten langfristigen Prognosen, da neue Schüler eingeschult werden und alte Schüler entlassen. Damit ändern sich auch die Schulwege.
Möglich wäre, dass bei späterem Schulbeginn Schüler, welche weiter entfernt wohnen, sich doch für unsere Schule entscheiden. Dadurch könnte sich der Durchschnitt des Schulweges insgesamt erhöhen. Andererseits gelten Bestimmungen der Schulbehörde, welche ich nicht überblicke, welcher Schüler in welche Schule eingeschult werden darf. So bleibt mir nicht anderes übrig, als von den aktuellen erhobenen Daten auszugehen.
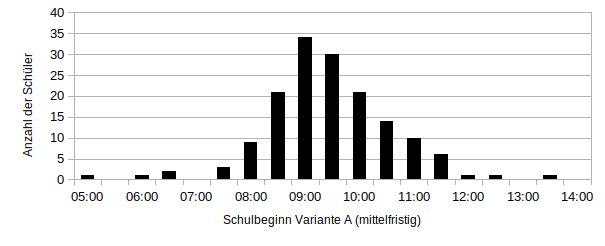
Variante A: Ich nehme für alle Schüler die durchschnittliche persönliche Zeit am Morgen an. Der Schulweg bleibt der individuelle Wert. Die Verteilung sieht wie folgt aus:
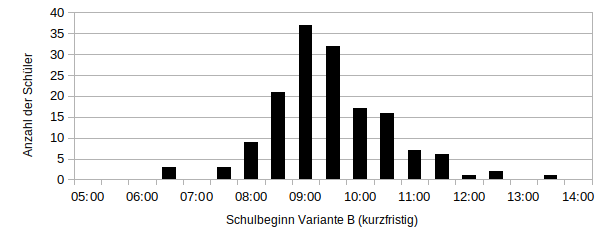
In der Variante B übernehme ich die Zeit, die ein Schüler bisher gebraucht hat vom Aufstehen bis zum Schulbeginn und addiere sie zu der natürlichen Aufwachzeit. Dann ergibt sich folgende Verteilung:
Die Variante C nimmt nur die Verteilung der Aufwachzeit und verschiebt sie um den Durchschnitt der Schulwege (~30min) sowie der persönlichen Zeit am Morgen (~1h):
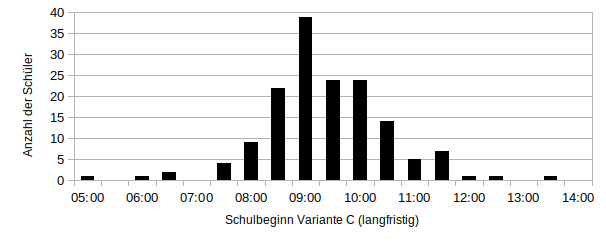
Die Variante C hat den Vorteil, dass nur die natürliche Aufwachzeit verschoben wurde. So handelt es sich hier weiterhin um eine Normalverteilung, für die ich eine Funktion angeben kann.
Die Verteilungen sehen auf dem ersten Blick sehr ähnlich aus. Mit Mittelwert und Standardabweichung, kann man die Kurven sehr gut vergleichen. Um auf die Forschungsfrage zurück zu kommen, ob die Schule zu zeitig beginnt, ermittele ich außerdem den Prozentsatz an Schülern, die 7:35 Uhr oder eher bereit für die Schule wären. Als gute Größe um Ausreißerwerte zu vernachlässigen wird der Median statt des Mittelwertes genutzt.
| Variante A | Variante B | Variante C | Variante C* | |
| Mittelwert | 9:26 Uhr | 9:26 Uhr | 9:26 Uhr | 9:28 Uhr* |
| Standardabweichung | 1h 5 min | 1h 9 min | 1h 9 min | 1h 12 min* |
| Teilnehmer, die 7:35 Uhr bereit sind | 6 | 4 | 5 | |
| Prozentsatz | 3,8% | 2,8% | 3,2% | 5,8% |
| Median | 9:22 Uhr | 9:21 Uhr | 9:17 Uhr |
Egal, welche Variante ich wähle, es wird klar, dass die Schule deutlich zu zeitig anfängt. Einen optimalen Schulbeginn gibt es nicht. Am besten wäre es natürlich, die Schule würde zwischen der spätesten Aufwachzeit und der frühesten Einschlafzeit liegen. Das wäre zwischen 12 (+Schulweg) und 21 (-Schulweg) Uhr. Da aber in der Gesellschaft verankert ist, dass die Schule vormittags beginnt, damit nachmittags und abends Zeit für Hobbys ist, wird dieser Plan schwierig. Ein Kompromiss wäre sicherlich der Median, also die Schule ungefähr um 10 vor halb 10 beginnen zu lassen. Realistisch ist das allerdings immer noch nicht. Im sächsischen Schulgesetz (Schulordnung Gymnasien Abiturprüfung § 19 Absatz 2) ist der Schulbeginn zwischen 7 und 9 vorgeschrieben. Damit wäre aus biologischer Sicht 9:00 Uhr am besten. Bezieht man noch den ÖPNV ein, wäre zunächst 8:35 Uhr anzustreben, da das für unsere Schule kaum einen Unterschied macht, weil die allermeisten Busse, Bahnen und Züge mindestens stündlich fahren.
2. Fällt es einem Teenager mit zunehmendem Alter immer schwerer, zeitig aufzustehen?
Für die Schätzung einer Regressionsgerade werden zunächst die Wertepaar in ein Koordinatensystem eingetragen.
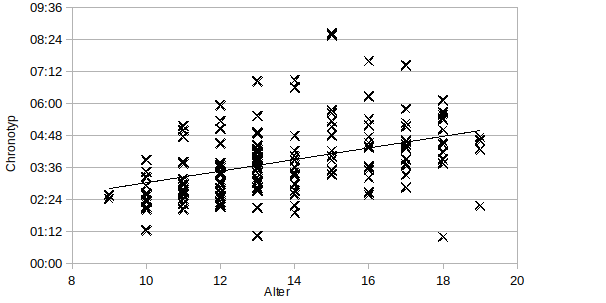
Man erkennt eine Punktwolke mit linearer Tendenz. Die Stärke kann mit dem Korrelationskoeffizient r ausgedrückt werden.
mit X = Alter und Y = Chronotyp
Aus den Daten ergibt sich:
Nach einsetzen erhält man
Damit liegt ein stochastischer linearer Zusammenhang mittlerer Stärke vor. Die Art der linearen Abhängigkeit wird durch bYX vorgegeben.
Das bedeutet, der Chronotyp verschiebt sich mit zunehmendem Alter in der Jugend um durchschnittlich 13,1 Minuten nach hinten pro Jahr.
Spannend ist aber nicht alleine der Chronotyp. Denn wenn sich die Schlafdauer verkürzt, könnte es sein, dass dieser Effekt gar keine Rolle spielt. Deswegen betrachte ich nun die biologische Aufwachzeit in Abhängigkeit des Alters.
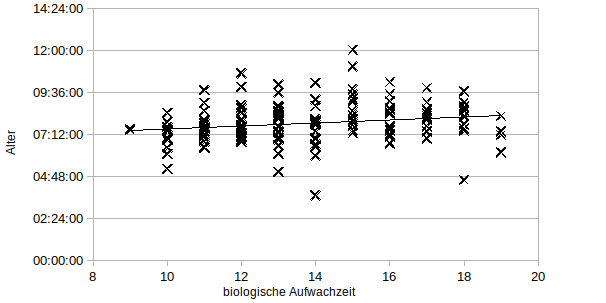
Die Punktwolke ist dichter, dafür scheint die lineare Abhängigkeit deutlich geringer zu sein. Ich berechne erneut r und bYX mit X = Alter und Y = biologische Aufwachzeit. Aus den Umfrage Daten erhält man:
Hier liegt nur noch stochastische Abhängigkeit schwacher Stärke vor.
Das bedeutet mit zunehmendem Alter wachen Jugendliche um durchschnittlich 5,1 Minuten später auf pro Jahr. Das würde für Zwölftklässler einen späteren Unterichtsbeginn von ca. 30 min rechtfertigen. Praktisch lässt sich so eine kleine Differenz im Schulalltag nicht berücksichtigen. Man kann aber für die Oberstufe statt der 1. Stunde lieber am Nachmittag noch eine Stunde länger unterrichten. In eine Empfehlung für die Schule würde ich dies aber nicht mit einbeziehen, da ein allgemeiner späterer Schulanfang viel mehr Nutzen bringt als diese Berücksichtigung der altersspezifischen Unterschiede.
3. Gibt es einen Unterschied zwischen Mädchen und Jungen bezüglich der Schlafenszeiten?
Zunächst trenne ich die Stichproben nach männlich und weiblich. Ich erhalte nun zwei Verteilungen, deren Mittelwerte ich vergleichen möchte.
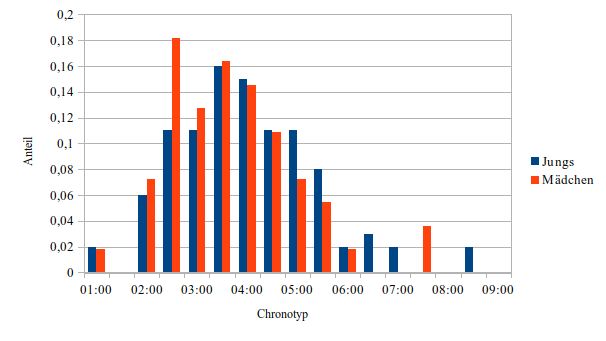
| männlich | weiblich | |
| Stichprobenumfang | 100 | 55 |
| Anzahl Klassen | 8 | 5 |
| Mittelwert | 3:59 Uhr | 3:42 Uhr |
| Varianz | 1,95 h² | 1,57 h² |
| Standardabweichung | 1,396 h | 1,252 h |
| X² | 6,989 | 15,337 |
| Statistische Signifikanz | 70% | 99,9% |
Mittels t-Test kann ich nun überprüfen, ob die Mittelwerte übereinstimmen oder nicht.
Damit kann die Nullhypothese, dass die Mittelwerte der zwei Gruppen übereinstimmen, auf dem 10%-Niveau abgelehnt werden. Die hier übliche Grenze ist 1%, damit man annehmen kann, dass es sich um zwei unterschiedliche Gruppen handelt. Hier ist in einem von 10 Fällen doch kein Unterschied zwischen Mädchen und Junge. Damit kann ich über den Unterschied zwischen Mädchen und Jungen keine belastbare Aussage treffen